隨著大數(shù)據(jù)技術(shù)的快速發(fā)展,Apache Spark作為主流的大數(shù)據(jù)處理框架,已成為眾多企業(yè)招聘大數(shù)據(jù)工程師時的必考內(nèi)容。本文整理了Spark面試中的核心知識點和常見問題,幫助求職者系統(tǒng)準備。
一、Spark基礎(chǔ)概念
1. Spark與Hadoop MapReduce的主要區(qū)別是什么?
Spark基于內(nèi)存計算,執(zhí)行速度比MapReduce快10-100倍;提供豐富的API(Scala、Java、Python、R);支持流處理、機器學(xué)習(xí)等更多計算模式。
2. 解釋Spark的核心組件
? Spark Core:提供基本功能,包含任務(wù)調(diào)度、內(nèi)存管理、容錯機制
? Spark SQL:用于處理結(jié)構(gòu)化數(shù)據(jù)的模塊
? Spark Streaming:實時流數(shù)據(jù)處理
? MLlib:機器學(xué)習(xí)算法庫
? GraphX:圖計算庫
二、RDD核心知識點
1. 什么是RDD?其主要特性有哪些?
RDD(彈性分布式數(shù)據(jù)集)是Spark的基本數(shù)據(jù)結(jié)構(gòu),具有:
? 分區(qū)性:數(shù)據(jù)被分割成多個分區(qū)
? 容錯性:通過血緣關(guān)系實現(xiàn)數(shù)據(jù)重建
? 不可變性:創(chuàng)建后不能修改
? 并行操作:支持并行處理
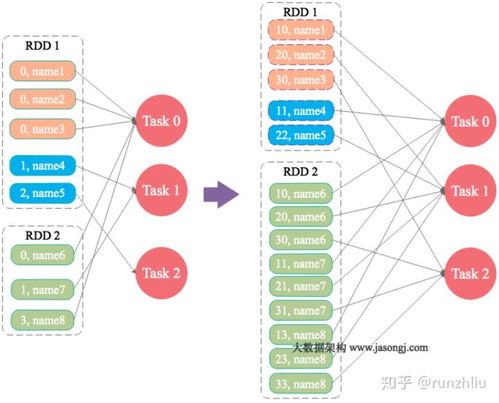
2. RDD的兩種操作類型
? 轉(zhuǎn)換操作(Transformation):懶執(zhí)行,如map、filter、groupByKey
? 行動操作(Action):觸發(fā)計算,如count、collect、saveAsTextFile
三、Spark運行架構(gòu)
1. Driver Program和Executor的作用
Driver是應(yīng)用程序的主進程,負責創(chuàng)建SparkContext、調(diào)度任務(wù);Executor是工作節(jié)點上的進程,負責執(zhí)行具體任務(wù)和存儲數(shù)據(jù)。
2. Spark任務(wù)執(zhí)行流程
從RDD對象構(gòu)建DAG圖 → DAGScheduler將DAG劃分為Stage → TaskScheduler將Task分發(fā)到Executor執(zhí)行。
四、性能優(yōu)化相關(guān)問題
1. 如何避免Spark中的shuffle操作?
盡量使用reduceByKey代替groupByKey,因為前者會在map端進行combine操作,減少數(shù)據(jù)傳輸。
2. 什么情況下會出現(xiàn)數(shù)據(jù)傾斜?如何解決?
當某個key的數(shù)據(jù)量遠大于其他key時會發(fā)生數(shù)據(jù)傾斜。解決方案包括:
? 使用隨機前綴進行雙重聚合
? 調(diào)整并行度
? 使用廣播變量
五、實戰(zhàn)場景題
1. 假設(shè)有1TB的日志文件,如何統(tǒng)計每個IP的訪問次數(shù)?
sc.textFile("hdfs://...")
.map(line => (line.split(" ")[0], 1))
.reduceByKey( + )
.saveAsTextFile("output_path")
2. 如何實現(xiàn)Spark Streaming實時統(tǒng)計每5分鐘的PV?
使用window操作,設(shè)置窗口長度為5分鐘,滑動間隔為5分鐘。
六、進階問題
1. Spark SQL中DataFrame和Dataset的區(qū)別
DataFrame是Dataset[Row]的類型別名,Dataset是強類型的數(shù)據(jù)集合。
2. Spark on YARN的兩種部署模式
? Client模式:Driver在客戶端運行
? Cluster模式:Driver在YARN集群中運行
備考建議:
除了掌握理論知識外,建議實際編寫Spark代碼,理解不同操作的執(zhí)行原理。同時關(guān)注Spark 3.x的新特性,如動態(tài)分區(qū)裁剪、自適應(yīng)查詢執(zhí)行等優(yōu)化功能。面試時要準備好項目經(jīng)驗分享,展示解決實際問題的能力。